
| SNAP GPF |
|
Within SNAP, the term data processor refers to a software module which creates an output product from one or more input products configured by a set of processing parameters. A product is basically a collection of bands which again provide numerical raster data for a spectral radiance, geophysical property or quality flag. The GPF was originally developed for BEAM. The first version of BEAM was released end of the year 2002 and included data processors used for MERIS Smile Effect Correction and Atmospheric Correction for MERIS, for computation of the AATSR Sea Surface Temperature and to generate general Level 3 products using the SeaWiFS binning algorithm. Since this time, a number of data processors have been developed; some of them are standard modules while others are contributed by 3rd parties. All of these data processors have been developed using a dedicated processing framework which was already part of the first version of BEAM. It enforces a programming model in which developers have to implement the three obvious lifecycle phases of a processor:
Although the programming model is very simple and has been accepted by many users, it has some important shortcomings. The major issue is that programmers have to explicitly deal with files. They have to open data product files to read samples from and physically create an output product file to write samples to. What is wrong with that? First, data processers operating in a chain of operations are hereby bound to in-between file I/O. But in many cases, file I/O is what accounts for most of the total processing time, even when performed on the local file system. Secondly, parallelisation by exploiting multi-core CPUs using multi-threading is difficult to implement as long as developers are responsible for the I/O in their data processor code. Furthermore, implementing multi-threading in general can be become a difficult task and can mess up the code. Finally, developers of a scientific data processor should simply not have to deal with low level issues such as I/O and multi-threading. Instead they should focus solely on the implementation of the algorithm.
Based on the experience collected within a number of projects, the authors have developed what is now the SNAP Graph Processing Framework (GPF). The GPF addresses all the issues mentioned above, adds a number of new features for developers, reduces the amount of source code to write while drastically improving its readability and maintainability.
As its name states, the GPF allows to construct directed, acyclic graphs (DAG) of processing nodes. A node in the graph refers to a GPF operator, which implements the algorithm to be executed. The node also has the role to configure the operation by specifying the operator's source nodes and providing values for the processing parameters. The main difference to the BEAM processing framework is an inversion of the execution flow. Using the earlier processing framework, the developer was responsible to control the way how the output product is written. Using the GPF, the framework controls the execution flow by requesting the computation of target samples from the GPF operator. In turn, the operator will request source samples from one or more predecessor nodes. This execution flow is also referred to as pull processing, because each node pulls at its source node first in order to perform the algorithm it implements. The actual processing of a graph is triggered by requesting samples from one of its nodes. This may happen because an image needs to be displayed in a graphical user interface or by writing the samples of a final target product to a file.
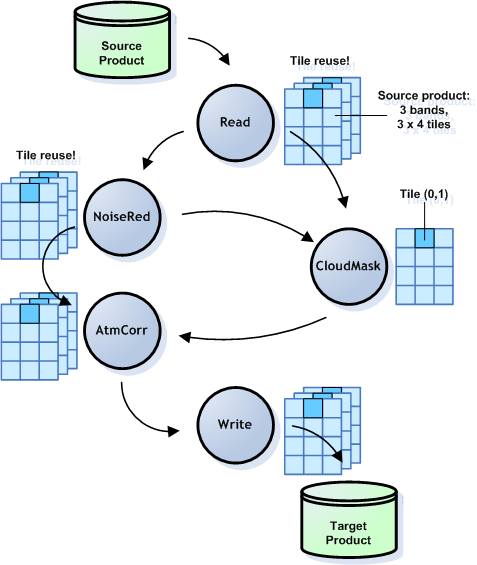
A processing graph comprising five nodes. Graph pull-processing is triggered by the "Write" operation requesting tiles from its source node.
Using this approach, an intermediate disk I/O is not required anymore; instead intermediate samples are transferred and cached in-memory. Additionally, GPF can automatically use multiple threads for parallel computation in order to exploits multi-core CPUs.
Most of the algorithms used in optical EO data convert measured radiances to higher level physical properties, such as ocean water constituents. In the following, we refer to a physical property using the term band. In general, a GPF operator implements how vectors of bands of source products are transformed into a vector of bands of the single target product of the operator. The GPF supports the development of two types of algorithms for that transformation: Algorithms which are designed to output the vector of their target bands at once and others which can compute each of their target bands independently of each other. This determination is important with respect to the runtime performance in different use cases, namely displaying an image interpretation of single band or writing the entire target product to disk. Many Level-2 algorithms are based on an inversion of some kind of Radiative Transfer Model and therefore naturally output a number of physical properties at once.
Many SNAP EO Data Processors are implemented as GPF operators and can be invoked via the Windows or Unix
command-line using the GPF Graph Processing Tool gpt
which can be found in the bin directory of your Sentinel Toolbox installation.
Most of them also have dedicated user interfaces in the Sentinel Toolbox.
The list of available GPF operators bundled with SNAP is given in the Operator
Index.